Gannicus
Свой
- 2 Янв 2014
- 307
- 948


Давайте рассмотрим еще один бесплатный парсер выдачи Google GScraper. Парсер является лучшим в своем роде благодаря высокой скорости парсинга, возможности настраивать парсер под различные нужды, ну и конечно бесплатности.
После запуска парсера мы видим три вкладки «Proxy», «Options» и «Scrape» в которых можно задать соответствующие настройки (ввести прокси-лист, задать таймаут, максимальное количество потоков, указать файл для экспорт а результатов парсинга, получить тайтлы спарсенных URL и т.д.). Оставим эти настройки по умолчанию. Прокси использовать не будем. При длительном парсинге без прокси конечно не обойтись, поэтому если будете парсить много и долго запасайт есь рабочими прокси.
Давайте для примера спарсим сайты, построенные на движке DLE для последующей регистрации на них.
Переходим на вкладку «Scrape» и вводим признаки DLE и ключевое слово для парсинга: Footprint(s) — «index.php?do=register», Keywords – “регистрация”. Жмем «Start scrape»
Как видите, за 13 секунд парсер нашел 739 URL. Теперь давайте очистим результаты от дубликатов, нам необходимо удалить дубликаты доменов. Для этого выбираем «Remove duplicate domain» и жмем «Do». В результате осталось 385 сайтов. Теперь таким же образом определим PR оставшихся сайтов, количество страниц в индексе Google и тайтлы страниц выбирая соответствующие опции и нажимая «Do».
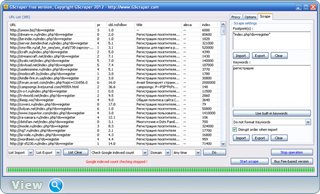
Как видите, некоторые сайты из выдачи не являются сайтами DLE, например можно увидеть форум Аваста. Это потому, что на странице форума, скорее всего, обсуждаются признаки DLE и среди них «index.php?do=register». Поэтому если будете парсить сайты DLE, лучше воспользуйтесь таким запросом: «inurl:»index.php?do=lostpassword» пароль».
Теперь можно сохранить полученные результаты (только ссылки или полностью все колонки).
Скачать GScraper можно с :
После запуска парсера мы видим три вкладки «Proxy», «Options» и «Scrape» в которых можно задать соответствующие настройки (ввести прокси-лист, задать таймаут, максимальное количество потоков, указать файл для экспорт а результатов парсинга, получить тайтлы спарсенных URL и т.д.). Оставим эти настройки по умолчанию. Прокси использовать не будем. При длительном парсинге без прокси конечно не обойтись, поэтому если будете парсить много и долго запасайт есь рабочими прокси.
Давайте для примера спарсим сайты, построенные на движке DLE для последующей регистрации на них.
Переходим на вкладку «Scrape» и вводим признаки DLE и ключевое слово для парсинга: Footprint(s) — «index.php?do=register», Keywords – “регистрация”. Жмем «Start scrape»
У вас нет прав на просмотр ссылок, пожалуйста: Вход или Регистрация
Как видите, за 13 секунд парсер нашел 739 URL. Теперь давайте очистим результаты от дубликатов, нам необходимо удалить дубликаты доменов. Для этого выбираем «Remove duplicate domain» и жмем «Do». В результате осталось 385 сайтов. Теперь таким же образом определим PR оставшихся сайтов, количество страниц в индексе Google и тайтлы страниц выбирая соответствующие опции и нажимая «Do».
Как видите, некоторые сайты из выдачи не являются сайтами DLE, например можно увидеть форум Аваста. Это потому, что на странице форума, скорее всего, обсуждаются признаки DLE и среди них «index.php?do=register». Поэтому если будете парсить сайты DLE, лучше воспользуйтесь таким запросом: «inurl:»index.php?do=lostpassword» пароль».
Теперь можно сохранить полученные результаты (только ссылки или полностью все колонки).
Скачать GScraper можно с :
Для просмотра скрытого контента необходимо Войти или Зарегистрироваться.
Последнее редактирование модератором:
